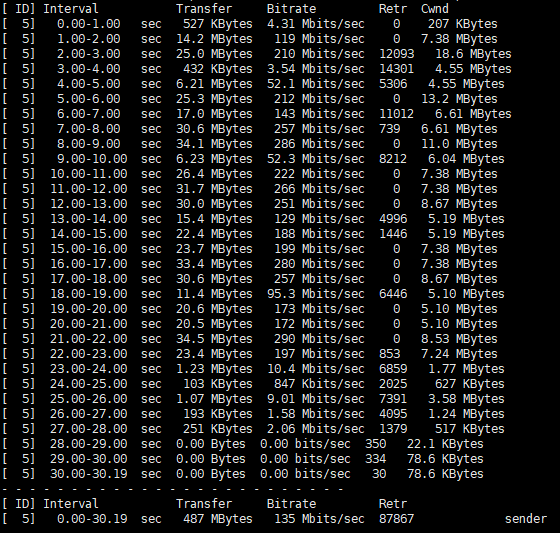
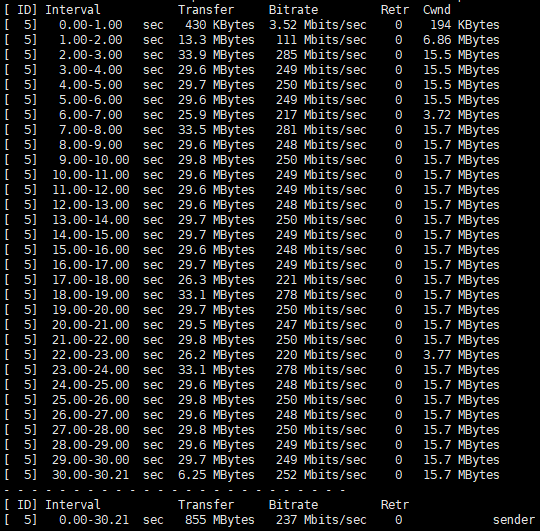
在应用场景需要处理大量的流量和复杂的规则集,nftables完全运行在内核空间,减少了上下文切换的开销,性能和灵活性方面都优于iptables。
nftables端口转发的:
优点:基于内核,工作在传输层,转发效率高,适合内网和延迟低的网络。
缺点:不支持BBR拥堵算法(因为BBR工作在应用层)
流量走向:
客户端 -- A服务器 -- B服务器(落地) -- 目标 -- 返回B服务器(落地)
中转服务器IP:2.2.2.2 端口:2222
目标服务器IP:6.6.6.6 端口:6666
实现目的:把本机A服务器IP 2.2.2.2 上的 2222 端口流量转发到B服务器IP 6.6.6.6 的 6666 端口上
A服务器
以下都在A服务器上操作,也就是转发服务器,白话就是线路好的服务器
首先在服务器上开启内核转发:
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
使其生效:
sysctl -p
1. 安装 nftables
确保系统已经安装 nftables。在大多数 Linux 发行版中可以通过以下命令安装(Debian12 已默认自带,不用额外安装):
apt install nftables # 对于 Debian/Ubuntu
yum install nftables # 对于 CentOS/RHEL
2. 启用并启动 nftables
确保 nftables 服务已启用并运行:
systemctl enable nftables
systemctl start nftables
3. 创建或编辑配置文件
编辑 nftables 配置文件,通常位于 sudo nano /etc/nftables.conf,或者创建一个新的配置文件。
以下是一个端口转发的配置示例:
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
chain input {
type filter hook input priority 0;
ct state { established, related } accept
ct state invalid drop
# 按需添加其他输入规则(如允许 SSH)
}
chain forward {
type filter hook forward priority 0;
ct state { established, related } accept
ct state new accept # 允许新转发连接
ct state invalid drop
}
chain output {
type filter hook output priority 0;
ct state { established, related } accept
}
}
table ip forwardaws { # 修正表名拼写
chain prerouting {
type nat hook prerouting priority -100;
# 仅对新连接执行 DNAT
tcp dport 2222 ct state new dnat to 6.6.6.6:6666
udp dport 2222 ct state new dnat to 6.6.6.6:6666
} # 正确闭合 prerouting 链
chain postrouting {
type nat hook postrouting priority 100;
ip daddr 6.6.6.6 masquerade
}
}
4. 加载配置
保存文件后,通过以下命令加载配置:
nft -f /etc/nftables.conf
5. 验证规则
使用以下命令查看当前 nftables 规则是否正确加载:
nft list ruleset
prerouting 链:用于修改进入主机的数据包,适合端口转发。
postrouting 链:用于修改发出主机的数据包,通常用于地址伪装 (SNAT)。
B服务器(落地)
B服务器也就是落地服务器
转发多个端口代码如下:
中转服务器IP:2.2.2.2 端口:2222
目标服务器IP:6.6.6.6 端口:2222
目标服务器IP:8.8.8.8 端口:3333
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
chain input {
type filter hook input priority 0;
ct state { established, related } accept;
ct state invalid drop;
# Allow SSH (example)
# tcp dport 22 accept;
}
chain forward {
type filter hook forward priority 0;
ct state { established, related } accept;
ct state new accept; # Allow new forwarded connections
ct state invalid drop;
}
chain output {
type filter hook output priority 0;
ct state { established, related } accept;
}
}
table ip forwardaws { # Corrected table name
chain prerouting {
type nat hook prerouting priority -100;
# DNAT rules (separate per port)
tcp dport 2222 ct state new dnat to 6.6.6.6:2222;
tcp dport 3333 ct state new dnat to 8.8.8.8:3333;
}
chain postrouting {
type nat hook postrouting priority 100;
ip daddr { 6.6.6.6, 8.8.8.8 } masquerade;
}
}
原始配置:
#!/usr/sbin/nft -f
flush ruleset
# 创建一个名为 "fowardaws" 的表,用于转发流量
table ip fowardaws {
# 在 prerouting 链中配置 DNAT(目的地址转换)
chain prerouting {
# 设置该链的类型为 NAT(网络地址转换),并在 prerouting 阶段生效
type nat hook prerouting priority -100; # priority -100 表示较早匹配规则
# 将本机也就是中转机2222端口流量转发到落地机IP(6.6.6.6)的6666端口上
tcp dport 2222 dnat to 6.6.6.6:6666
udp dport 2222 dnat to 6.6.6.6:6666
# 上述两行规则会将访问本机 2222 端口的 TCP/UDP 流量重定向到指定的远程服务器端口
}
# 在 postrouting 链中配置 SNAT(源地址转换)
chain postrouting {
# 设置该链的类型为 NAT,并在 postrouting 阶段生效
type nat hook postrouting priority 100; # priority 100 表示在路由后生效
# 使用 masquerade(伪装)机制,将流向(目的机器的ip) 的流量的源地址转换为本机的出站 IP 地址
ip daddr 6.6.6.6 masquerade
# masquerade 的效果是隐藏本地 IP,使目标服务器看到的是中转机的外网 IP,而非局域网 IP
}
}